Cortif AI announces an enterprise partnership with Forvis Mazars to advance secure and reliable AI infrastructure.Cortif AI announces an enterprise partnership with Forvis Mazars. Read the announcements →
Complete visibility into your LLM stack
Monitor, reroute, analyze, and optimize your LLM's in real-time. From token usage to sentiment analysis, Noah gives you the insights you need to scale with confidence.
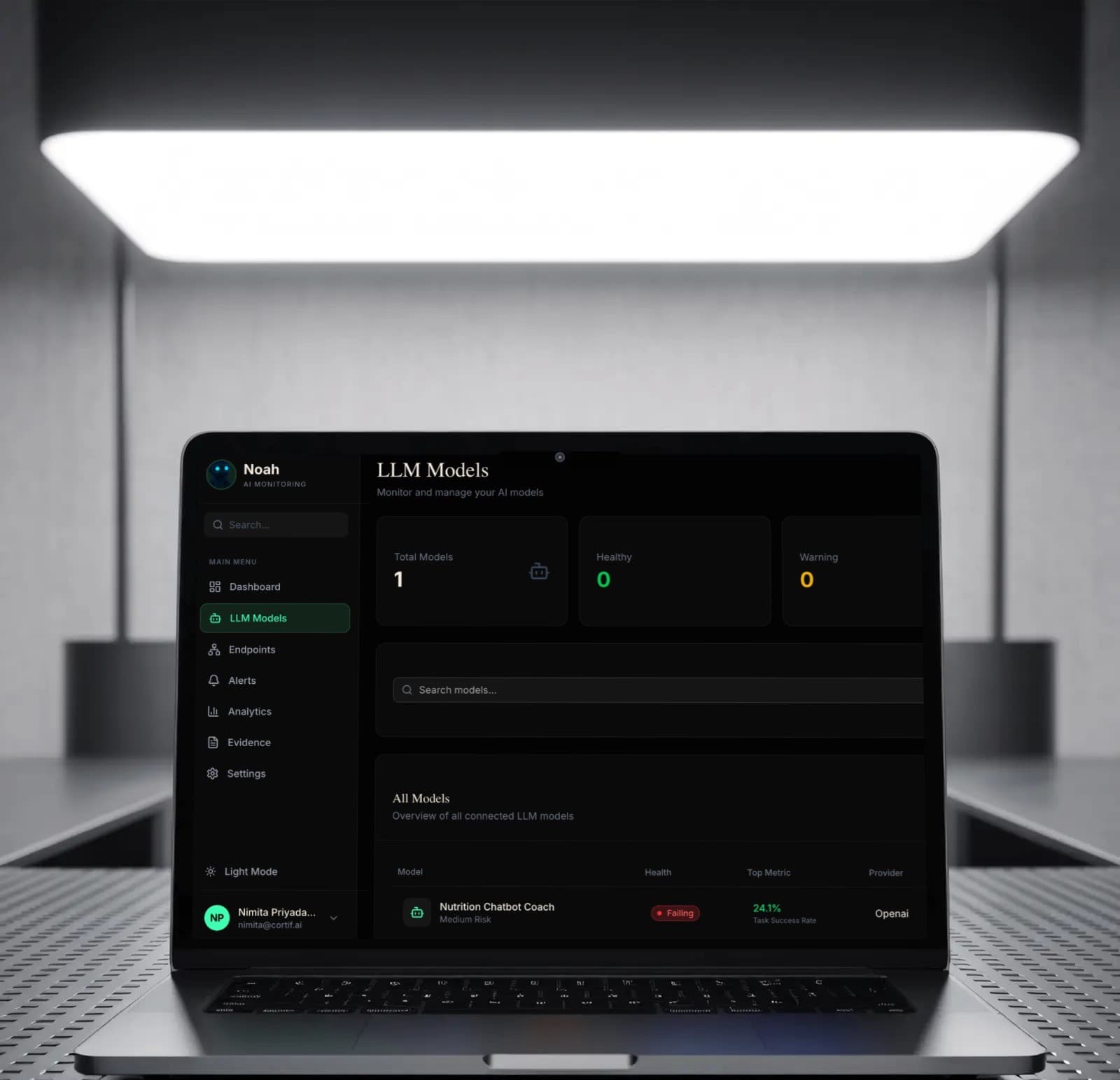
Real-time insights for mission-critical models.
Don’t fly blind. Track latency, throughput, and error rates as they happen. Our dashboard updates instantly, allowing you to catch regressions before your users do.
- ✓Live token usage tracking per request
- ✓P95 and P99 latency monitoring
- ✓Detailed error rate breakdown by model type
- ✓Auto model switching on performance or cost spikes
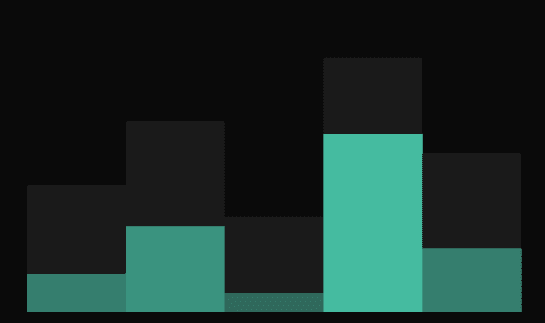
Latency (ms)
Input Prompt
“Generate a response regarding the competitor’s pricing model...”Analysis Result
Sentiment: Neutral
PII Detected: None
Topic Drift: High Confidence
Under stand what your models are saying.
Go beyond simple metrics. Noah analyzes the semantic content of every interaction to ensure safety, quality, and alignment with your business goals.
- ✓Automated PII detection and reduction
- ✓Sentiment and tone analysis
- ✓Drift detection for long-running conversations
- ✓Latency optimization and routing across providers
Model Behavior Forecasting
Predict how upcoming model releases will impact your production systems before they ship. Proactively reroute or adjust prompts so updates never break your AI.
Intelligent Prompt Optimization
Automatically rewrite and compress prompts to reduce token usage without losing output quality. Lower costs and lower latency without touching your code.
Agentic Workflow Monitoring
Track every LLM call inside multi step agent pipelines in real time. Detect loops, cost spirals, and silent failures before they cascade.
Anomaly Detection & Auto-Healing
Noah detects performance degradation the moment it starts—and fixes it automatically. No alerts, no on-call engineer, no firefighting.
Multi-Provider Cost/Quality Benchmarking
Continuously benchmark every model across your actual workloads not synthetic tests. Know exactly which model is best for each task, updated in real time.
On-premise & Compliance
Full audit trail of every AI decision and on-premise deployment for regulated industries. Zero compromises on security or compliance.
Ready to optimize your models?
Join engineering teams at leading AI companies who trust Noah for their observability stack.